
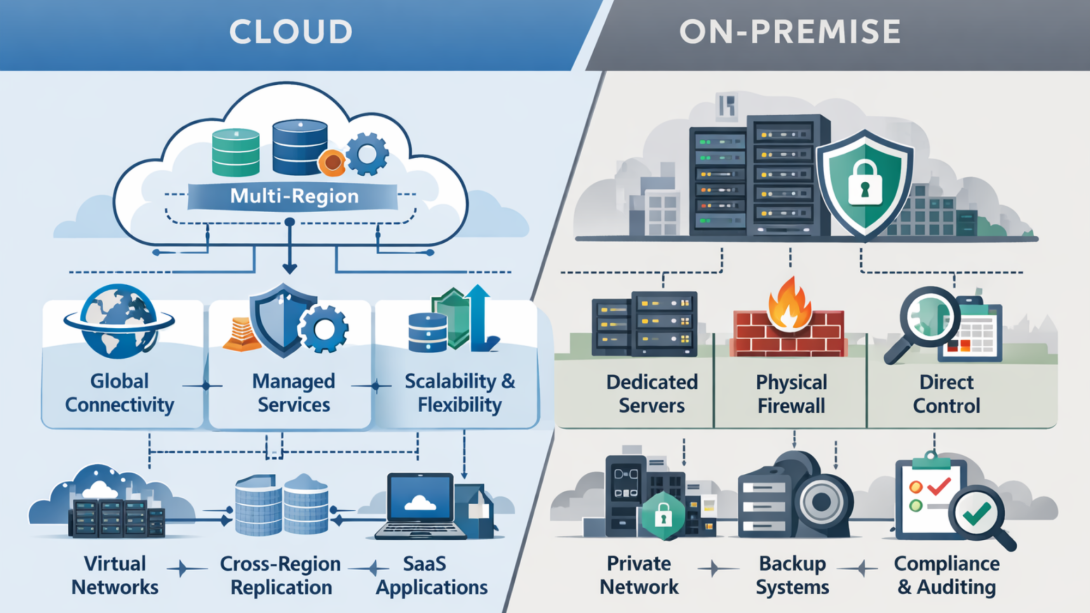
Most enterprise networking discussions still frame the decision as on-premise versus cloud. In reality, that framing is outdated.
Over the past year, networking decisions have been tested by real operational pressure—regional outages, rising inter-service traffic, unpredictable costs, and tighter compliance expectations. What emerged wasn’t a clear winner, but a clearer understanding of where assumptions failed and where architectures held up.
Cloud networking delivered speed and scale, but exposed gaps in visibility, ownership, and cost predictability as environments matured. On-premise networking, often considered legacy, quietly proved its value in latency-sensitive, regulated, and operationally stable environments where predictability mattered more than elasticity.
What’s notable is how experienced teams responded. Instead of committing to a single model, they shifted to workload-led decision making. Some systems stayed in the cloud. Others remained on-premise. Many adopted deliberate hybrid designs—not as a compromise, but as a way to control risk, isolate failures, and make responsibilities explicit.
This article explores how infrastructure leaders, cloud architects, and CTOs are actually making networking decisions today—based on operational outcomes rather than platform ideology. It’s a practical look at what breaks, what holds, and how mature teams design networks that withstand real-world pressure.